11 Different Types of Computer File Systems
By Puja Chatterjee on March 09, 2022What are the different types of computer file systems? The file system, which is often abbreviated as FS, on the whole refers to the representation of data in a structured form. It also comes with a set of metadata or a short description of the data.
The importance of this file system is that you will need to apply it to the storage while doing a format operation. There are different types of file systems, which this article will tell you about.
KEY TAKEAWAYS
- The different types of file systems in a computer are actually the logical disk component that compresses the files and are only useful for the computer and not the human user.
- Each file system may differ from the other in logic, structure, speed, properties, size, flexibility and security.
- The file systems can be categorized under different heads such as disk file, flat file, tape file, flash file, database file, network file, transactional file, minimal file, shared file, clustered file and special file.
The 11 Different Types of Computer File Systems
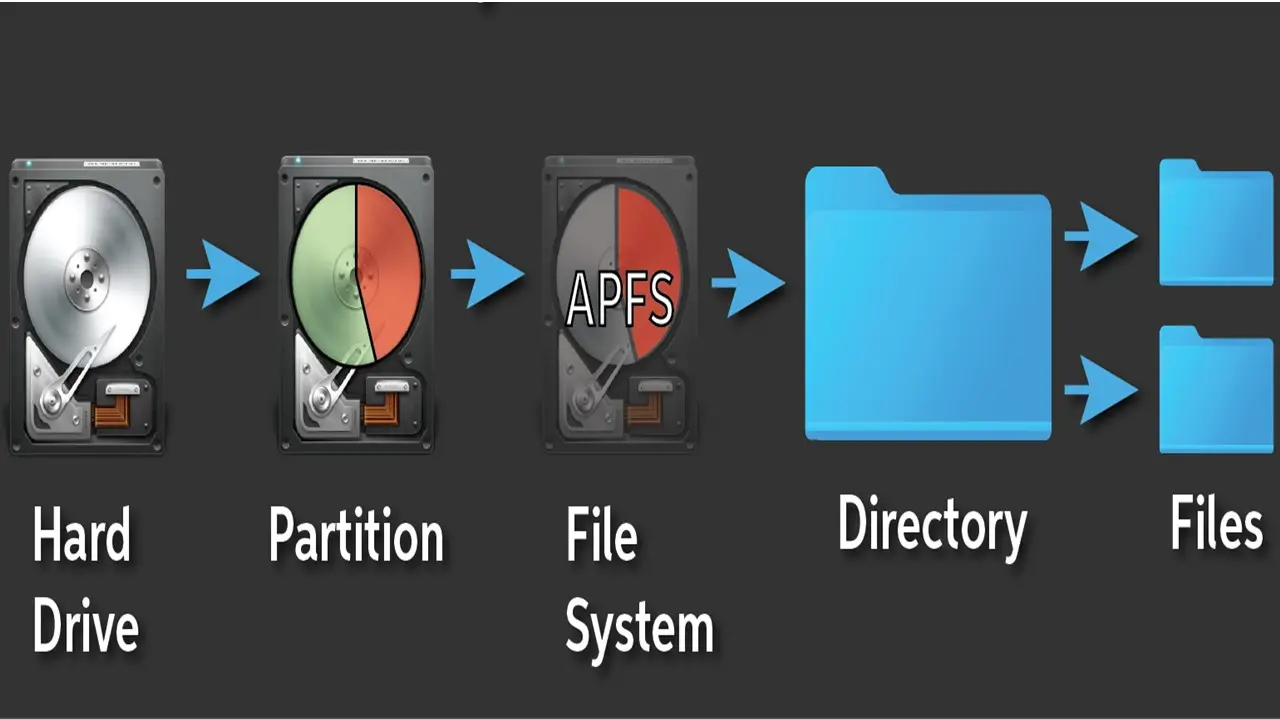
Technically speaking, a file system is a logical disk component. It compresses different files that are normally divided into groups called directories.
However, it is related to the computer and is nonrepresentational to the human user.
The primary objective of it is to administer the internal operations of the disk.
There is a wide range of file systems with Windows but the NTFS is the most widespread type in recent times.
In spite of the wide diversity of file systems, it is not possible for two files to exist in the same computer system with the same name.
Also, it is not possible to recover a particular file or to remove any installed programs without file management.
And, in absence of a file structure no file will have any organization.
All files in a computer system are typically handled in a hierarchy and it is the file system that allows the users to see them in the existing directory. In the directories there can be files as well as other directories.
Each of the several kinds of file systems is different from the other in several aspects such as:
- In logic
- In structure
- In properties
- In speed
- In security
- In flexibility
- In size and more.
A few of these files are also designed so that these can be used for different applications. For example, the ISO 9660 file system is intended to be used specially for optical discs.
Here are the major types of file system with their brief characteristics for you.
1. Disk File System:
A disk file system on a disk storage medium has the capability to address data randomly in a short period of time.
In addition to that, a disk file system also anticipates the speed of data accessibility.
This file system helps a large number of users to access different data on the disk irrespective of its sequential location.
Typically, the disk file system makes the best use of the available disk storage media and its ability in order to address data in quick time.
Further considerations are also needed to be made which include the data accessing speed following the anticipation and initial request of the data.
A few examples of disk file systems include:
- FAT12
- FAT16
- FAT32
- exFAT
- HFS
- HFS+
- HPFS
- NTFS
- APFS
- XFS
- UFS
- ZFS
- ext2
- ext3
- ext4
- btrfs
- Veritas File System
- Files-11
- VMFS
- ReiserFS and
- ScoutFS.
Few of these disk file systems are also versioning file systems or journaling file systems.
Considering the optical discs, the two common formats are UDF or Universal Disk Format and ISO 9660. These formats target the DVDs, Compact Discs, Blu-ray discs.
The UDF extension, Mount Rainier, supports Windows Vista and 2.6 series of the Linux kernel and helps in rewriting to DVDs.
2. Flash File System:
This specific type of file system is in charge of the performance and the limitations, along with the special capabilities of the flash memory.
A disk file system however can use a flash memory device commonly as the fundamental storage media but it is recommended that a specific file system designed especially for a flash device is used.
3. Tape File System:
The files in this particular file system are held on a tape. Since these tapes are magnetic, these are much more powerful and data can be accessed in them for a long time.
This overcomes the significant challenges that are typically offered for general purpose during file creation and management.
This is because the magnetic tapes used in this file system serves as a sequential storage media that has an extensively longer time for random data access as compared to disks.
Typically, there is a map of free and used data regions as well as a master file directory in a disk file system.
If any file is changed, added, or removed, it needs updating the directory as well as the maps.
This is required for every additional file write and this may take quite a long time for each file.
This works well for the disk file systems because the random access to the free and used data regions takes a fraction of a millisecond.
Read Also: What is Device Manager? (Explained)
However, the tape file systems need linear motion in order to unwind or wind the reels of the media that are practically very long.
It takes several seconds and even several minutes for the tape to move the read and write head on it from one end to the other.
Also, the usage map of data regions as well as the master file directory is pretty slow and quite ineffective with tape.
This means that writing will take a long time which characteristically entails finding free blocks for writing after reading the block usage map.
Similarly, updating the master file directory and the usage map to add further data and then moving the tape forward to write the data in the precise location also takes a long time.
The benefit of the tape file systems is that it typically allows spreading the file directory all over the tape intertwined with the data.
This is called streaming. This means that it does not need continual and time consuming tape motions for writing new data.
However, this needs reading the master file directory of the tape as well as scanning the whole tape to find out the directory entries that may be scattered all over it.
In order to avoid this need for rescanning the entire tape, most data archiving software that use this particular file system typically saves a local copy of the tape catalog on the disk file system. This ensures quick addition of files to the tape.
This local tape catalog copy is used for a specific period of time after which it is usually discarded making sure that it will not be used in the future by rescanning the tape.
The Linear Tape File System — Single Drive Edition or LTFS-SDE developed by IBM needs special mention at this point.
This particular tape file system utilizes a detached partition on the tape in order to document the index Meta data.
This eliminates the issues related with spreading the directory entries throughout the whole tape.
4. Database File System:
In this particular type of file system, the files are documented during management according to their characteristics rather than the traditional, hierarchical, and structured file management.
This includes characteristics such as the author of the file, type of file, the topic of it, similar Meta data and more.
This shows that this specific type of file management is based on the concept of database-based file system.
This particular technology is called the ‘Fortress Rochester’ which is a mix of a few fundamental aspects of early Mainframe technologies and is therefore more advanced from a technological point of view.
This is the technology that was designed by Frank G. Soltis, the former chief scientist for IBM, and his group at IBM Rochester within the period ranging from 1978 to 1988.
They successfully used database file system technologies in which Microsoft and others have failed.
For example, the IBM DB2 is such a database file system that incorporated a single level store and operated on IBM Power Systems and formed a part of the object based IBM operating system.
There are also a few other specific files systems that cannot be called database file systems purely but use a few specific aspects of it.
There are several web content management systems that utilize the RDBMS or the Relational Database Management System to store and retrieve files.
For instance, the XHTML files are stored as text fields or XML but the image files are stored as blob fields.
The SQL SELECT statements that have optional XPath typically retrieve files and allow using a complicated logic and richer information relations as compared to any other standard file systems.
There are also several CMSs that have the option to store the Metadata only in the database and the regular file system is used to store the substance of the files.
And, the extremely large file systems that are embodied by applications like Google File System and Apache Hadoop use some concepts of the database file system.
5. Transactional File System:
There may be a few particular programs that may need some multiple changes made to the file system or make no change at all if one or more of the changes turn out to be unsuccessful for whatever reason.
For example, a program might write the configuration files or executables and libraries at the time of updating or installing the software.
If this software stops working during the installation or updating process, it may become unusable or broken.
Apart from that, the entire system may be in an unusable state due to the incomplete installation and updating of the main system utility such as the command shell.
Typically, atomicity guarantee is introduced by transaction processing which ensures that every operation related to the transaction is either committed or the transaction itself can be aborted.
This will ensure that the system discards every bit of the partial transaction and its subsequent results.
This means that in the event of a power failure or a system crash, the data already stored in the system will be consistent and authentic even after recovery.
This signifies that either the software will be installed in its entirety or will be rolled back completely in case there is a failed or incomplete installation. There will be no partial and unusable installation remaining in the system.
Read Also: Computer Related Abbreviations & Full Forms
Moreover, isolation guarantee is also provided by transactions, which means that the operations inside the transaction will be out of sight from the other threads on the system until and unless the transaction itself commits.
This also signifies that all interfering operations on the system will be serialized in the right way with the transaction.
Initially, Windows started adding transaction support to NTFS starting with Vista as a feature called the Transactional New Technology File System. However, the use of it now is discouraged.
As for the UNIX systems, there are lots of research prototypes of transactional file systems which include:
- Amino file system
- LFS
- The Valor file system
- Transactional ext3 on the TxOS kernel and
- TFFS that targeted embedded systems.
Typically, with no file system transactions, it will be very difficult, if not impossible to ensure uniformity across the multiple file system operations.
You may argue that file locking may be used to control concurrency but then it will be possible only for the individual files and not necessarily be able to protect the Meta data of the file or the whole directory structure.
For example, file locking will not be able to prevent TOCTTOU or Time of Check to Time of Use race conditions on representational links.
Add to that, file locking is also unable to roll back any failed operation automatically such as a software or system upgrade. All these need atomicity.
However, there is one particular way in which consistency at transaction level can be introduced to the structures of the file systems. It is by using journaling file systems.
This is possible because the journal transactions are usually not revealed to programs as a part of the operating system using Application Program Interface or API.
These transactions are only used on the inside in order to ensure consistency at a granular level for a single system call.
Moreover, the data backup systems normally do not offer any support for direct backup of the data stored in a transactional mode.
This makes it very difficult to recover a consistent and reliable data set.
Most of the backup software merely notes the files that have changed within a specific period of time without considering the transactional state that may be shared across several files in the dataset on the whole.
In order to circumvent this issue, there are a few specific types of database systems that basically generate an archived state file.
This file contains all data up to that particular point and the backup software backs it up without interacting with the dynamic transactional databases directly at all.
When recovery is required, a disconnect recreation is needed of the database from the state file after that file is reinstated by the backup software.
6. Network File System:
These specific types of file systems, also known as NFS, allow the users to access the files that are stored on the server.
In the case of computers connected in a remote network, programs can be created and managed with the use of local interfaces. It also allows accessing the files and directories arranged in order.
A few examples of network file systems are clients for the NFS, file-system-like clients for FTP, SMB protocols, AFS, WebDAV and more.
7. Shared Disk File System:
A number of machines or servers in particular can access the same subsystem of external disk which is normally a SAN due to this shared disk file system.
However, when the machines do so there may be occurrences of collisions in such conditions.
Therefore, the file system itself decides which particular subsystem is to be accessed so that such chances of collisions can be prevented.
A few common examples of the shared disk file system are GPFS, GFS2 from Red Hat, SFS from DataPlow, StorNext from Quantum Corporation, CXFS or Clustered Extended File System designed by Silicon Graphics or SGI, and ScoutFS from Versity.
8. Minimal File System:
The disk and digital tape gadgets were very costly to use by a majority of microcomputer users in the 1970s.
Therefore, a few basic data storage systems were designed that were cheaper since these used a tape that is found in the common audio cassettes.
When the system needed to write data, the user had to press the ‘record’ button on the cassette recorder and at the same time press ‘Return’ on the keyboard to inform the system that the recording was being done by the cassette recorder.
In this process the system writes a sound in order to offer time synchronization. It then adjusted that sound by encoding it with a prefix, a suffix, the data and the checksum.
On the other hand, when the system needed to read the data, the users had to press the ‘Play’ button on the cassette recorder.
In this process the system listens to the sound on the tape and waits till an explosion of sound is documented as the synchronization.
Then, the system interprets the following sounds as data.
When the data reading is completed, the system then notifies the user to press the ‘Stop’ button on the cassette recorder.
This is considered to be a very archaic method to read and write data but it does work quite successfully.
Data can be stored in sequence generally in an unnamed format.
However, there are a few systems, for example the Commodore Personal Electronic Transactor or PET series of computers permit the files to be named.
Read Also: What is Green Computing? Types, Pros, Cons & More
In this process several sets of data can be written and located in quick time by the user.
This can be done by fast-forwarding the tape and watching the tape counter to find a reading that would indicate the fairly accurate starting point of the subsequent data region on the tape.
However, the users will have to listen to the sounds very carefully in order to find out the exact spot to start playing the next data region.
There are even a few specific implementations wherein audible sounds were mixed together with the data.
9. Flat File System:
In a flat file system, the subdirectories are not obtainable. Instead, it has only a single directory that holds all the data.
These file systems had comparatively a very little data space in them and therefore were just sufficient when the floppy disk media was accessible for the first time.
A flat file system featured in the CP/M or Control Program/Monitor machines that were later on called Control Program for Microcomputers.
Here the files can be allocated to any one of 16 user areas. This narrowed down the general file operations having to work only one area rather than all of them by default.
This means that the other user areas that were not assigned with a file were nothing more than just special attributes related to the files.
Therefore, it was not needed to define a precise quota for each of the areas. Instead, files can be added to groups for as long as free storage space is available on the disk.
One good example of a machine that featured a flat file system is the early Apple Macintosh.
It used the Macintosh File System which was unusual due to the fact that Macintosh Finder, its file management program, created an illusion of a partly hierarchical filing system on top of EMFS.
According to this particular structure, every file is required to have a unique name regardless of it appearing in a different folder.
Another good example is the IBM DOS/360 and OS/360 where the entries of all files are stored on a disk pack in a directory on it called a VTOC or the Volume Table of Contents.
Though the flat file system is quite simple, things really start to look awkward and become difficult as and when the number of files increases.
Then, it becomes almost impossible to organize the data into the associated groups of files.
And, Amazon’s S3 is the recent inclusion to the family of flat file systems. This is actually a remote storage service.
It is by design very simplistic which allows the users to customize the way they want their data to be stored.
It also allows advanced file management because the users can use any character including ‘/’ to name an object.
In addition to that, it offers the ability to the users to choose the subsets of the contents of the bucket based on the same prefixes.
10. Special File System:
There are also a few special file systems used that typically provide non-file elements of an operating system as files.
This helps in acting on them with the help of file system APIs. This is more commonly done on a Unix-like operating system.
However, the file names are also given to devices in a few specific non-Unix-like operating systems.
There are also a few other special file systems such as:
- sysfs and configfs in the Linux kernel that are typically used to query for information from the kernel and configure the entities in it and
- procfs that maps processes and structures into a file space on Linux and other operating system structures.
One specific special file system is the device file system that represents Input and output devices as well as a few pseudo-devices as files that are typically called the device files. A few examples of these file systems are:
- devfs in Unix-like systems and
- udev in Linux 2.6 systems.
As for the non-Unix-like systems like TOPS-10 and other operating systems, the complete pathname or filename may include only a device prefix that specifies the device and nothing following it.
11. Clustered File System:
These specific types of file systems allow distributed storage and are primarily used in computer cluster systems.
A few of the distributed file system types include:
- ZFS or Zettabyte File System that is developed by Sun Company for their Sun Solaris operating system
- Apple Xsan or the fruition of CentraVision and later StorNext of Apple
- VMFS or Virtual Machine File System that is developed by VMware Company for their VMware ESX server
- GFS or Global File System of Red Hat Linux and
- JFS1 or the legacy IBM JFS design that is used in older AIX storage systems.
These file systems come with a few common properties apart from supporting distributed storage such as modularity and extensibility.
Conclusion
So, now you have a general idea about the different types of file systems that are stored in a computer along with the characteristics of each of these types.
This surely has enhanced your knowledge regarding data management on any given storage.