Cache Only Memory Architecture, or COMA, is a unique approach to computer memory organization typically found in multiprocessor systems. Unlike traditional Non Uniform Memory Access (NUMA) architectures, COMA uses local memory such as Dynamic Random Access Memory (DRAM) as cache in each node. This fundamental difference sets COMA apart from its counterparts and offers some intriguing advantages.
At its core, COMA is a variant of Cache Coherent Non Uniform Memory Access (CC-NUMA) architecture. The key distinction lies in the shared memory module, which functions as a cache in COMA systems. Each memory line in COMA includes a tag containing:
- The state of the line
- The address of the line
When a CPU references a line, it may displace a valid line from memory, bringing its nearby locations into both local (NUMA) shared memory and private caches. This behavior gives COMA its name, as each shared memory effectively acts as a large cache.
Benefits of COMA
COMA enhances data availability locally by automatically replicating and transferring data to the currently accessed node's memory module. This feature significantly reduces the likelihood of recurring long latency during memory access, thanks to COMA's ability to adapt shared data more dynamically.
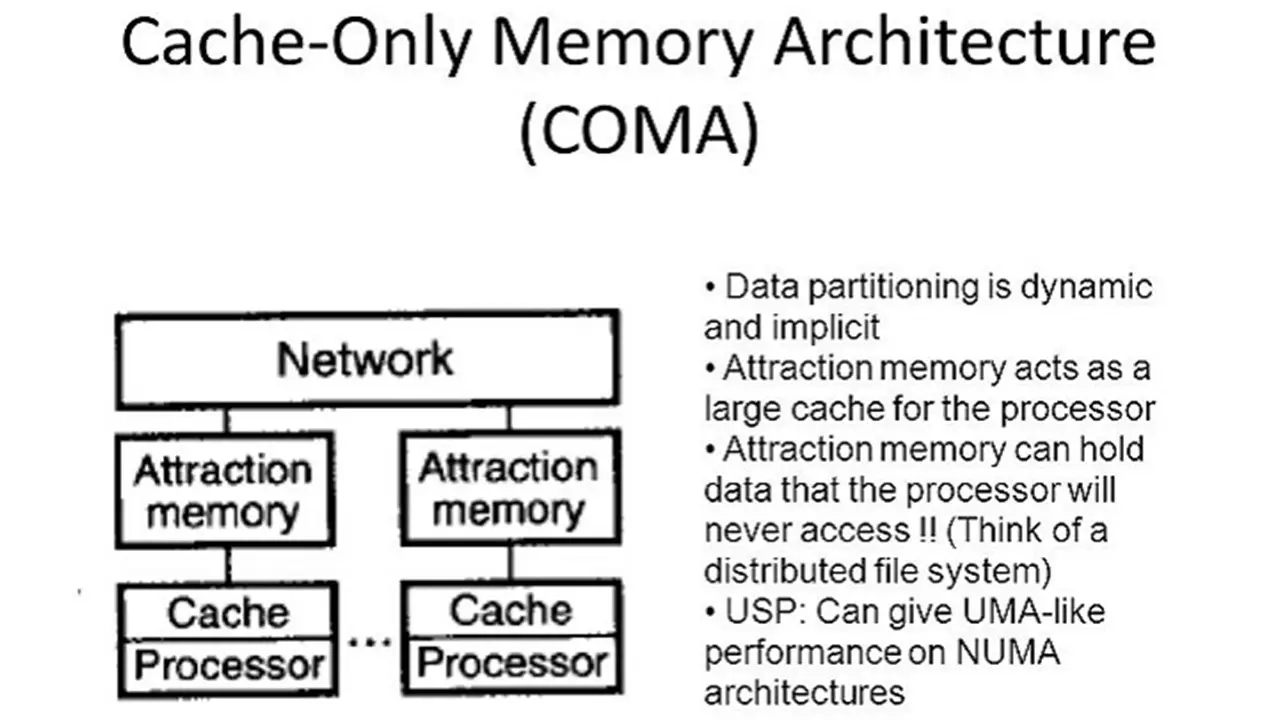
COMA Machine Structure
A typical COMA machine consists of multiple processing nodes connected through an interconnection network. Each node includes:
- A cache
- A high-performance processor
- A distribution of global shared memory
COMA machines differ from NUMA and CC-NUMA architectures by excluding primary memory blocks from local node memory and using only large caches as node memories. This approach eliminates issues related to static memory allocations found in NUMA and CC-NUMA machines.
Memory Resource Utilization
COMA allows for better utilization of memory resources compared to NUMA. In NUMA architectures, each address in the global address space is assigned a specific home node. COMA, on the other hand, has no home nodes, allowing data to migrate freely when accessed from a remote node. This flexibility reduces redundant copies and enables more efficient use of memory resources.
Challenges in COMA
Despite its advantages, COMA faces several challenges:
- Locating specific data due to the absence of home nodes
- Handling data migration when local memory is full
- Block replacement
- Block localization
- Memory overhead
Researchers have developed various solutions to address these issues, including:
- New migration policies
- Different forms of directories
- Policies for read-only copies
- Strategies for maintaining free space in local memories
Additionally, hybrid NUMA-COMA organizations have been proposed to combine the strengths of both architectures.
COMA Representatives
Two notable representatives of COMA architecture are:
Data Diffusion Machine (DDM): A hierarchical multiprocessor with a tree-like structure, implementing a non-parallel split-transaction bus.
KSR1: The first commercially available COMA machine, featuring a logically single address space realized by a group of local caches and the ALLCACHE Engine.
Alternative COMA Designs
To address latency issues in early hierarchical COMA designs, several alternative approaches were developed:
- Flat COMA: Uses a fixed location directory for easy block location.
- Simple COMA: Transfers some complexity to software while maintaining common coherence actions in hardware.
- Multiplexed Simple COMA (MS-COMA): Addresses memory fragmentation issues in Simple COMA by allowing multiple virtual pages to map to the same physical page.
Performance Considerations
When comparing COMA machines to other scalable shared-memory systems, several factors come into play:
- Memory overhead
- Cache miss categories (cold, coherence, and conflict misses)
- Data structure replication and migration
- Processor stall time
- Spatial locality and page-level access patterns
While COMA offers benefits in terms of transparent and fine-grain data migration and replication, it also faces challenges related to remote memory access costs and the complexity of cache coherence protocols.
The Future of COMA
As technology advances, the viability of COMA as an alternative architecture may be limited due to:
- Anticipated increases in relative remote memory access costs
- The need for simpler cache coherence protocols
- The potential for larger and more sophisticated remote caches to capture larger remote working sets without COMA support
Hybrid machines combining COMA features with the simplicity of NUMA-RC (NUMA with Remote Cache) may become the preferred design in the future.
Conclusion
Cache Only Memory Architecture offers a unique approach to memory organization in multiprocessor systems. While it presents challenges in implementation and performance, COMA's ability to adapt to application reference patterns dynamically provides advantages in data migration and replication. As computer architecture continues to evolve, the principles behind COMA may influence future hybrid designs, combining the strengths of multiple approaches to address the ever-growing demands of modern computing.