Instruction pipelining is a sophisticated method of implementing Instruction Level Parallelism (ILP) within a single processor. It's like an assembly line for instructions, where each step of instruction processing is handled simultaneously for different instructions. This technique keeps every part of the CPU busy, maximizing resource utilization and boosting overall performance.
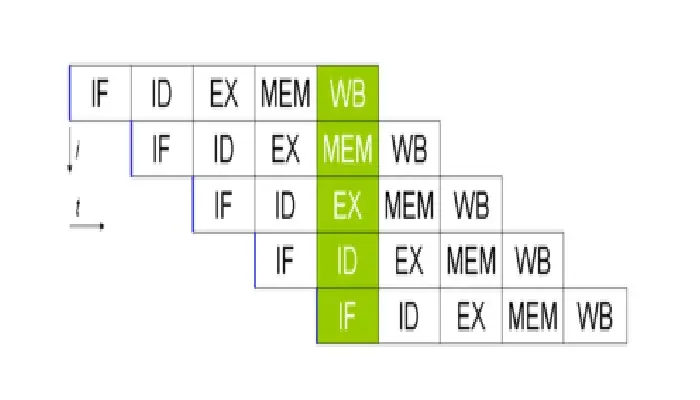
The Anatomy of an Instruction Pipeline
A typical instruction pipeline consists of several stages:
- Fetch: Retrieve the instruction from memory
- Decode: Interpret the instruction
- Address Calculation: Compute any memory addresses needed
- Operand Fetch: Retrieve necessary data
- Execute: Perform the actual operation
- Store: Save the result
Each stage is handled by a specific part of the processor, allowing multiple instructions to be in different stages of processing at the same time.
The Magic of Overlapping Execution
Imagine a CPU as a kitchen preparing meals. Without pipelining, it would be like cooking one dish at a time from start to finish. With pipelining, it's as if you're simultaneously chopping vegetables for one dish, cooking another, and plating a third. This parallel processing is the key to the efficiency gains of instruction pipelining.
Types of Pipeline Structures
- Instruction Fetch Unit: Uses a FIFO buffer to queue up instructions
- Instruction Execution Unit: Processes the queued instructions
This structure allows for continuous instruction fetching and execution, reducing memory access times and improving overall efficiency.
Challenges in Pipelining
While powerful, instruction pipelining isn't without its challenges:
- Pipeline Stalls: Also known as bubbles, these occur when the pipeline must pause due to resource conflicts or data dependencies
- Branch Prediction: Dealing with conditional branches can disrupt the pipeline flow
- Data Hazards: When instructions depend on the results of previous instructions still in the pipeline
Overcoming Pipeline Conflicts
To address these challenges, modern CPUs employ sophisticated techniques:
- Out-of-Order Execution: Allows instructions to be executed as soon as their operands are available
- Branch Prediction: Attempts to guess the outcome of conditional branches
- Register Renaming: Helps mitigate data hazards by using additional registers
The Impact of Instruction Pipelining
The benefits of instruction pipelining are substantial:
- Reduced CPU cycle time
- Increased instruction throughput
- Enhanced system reliability
- Simultaneous execution of multiple instructions
However, it's worth noting that pipelining also introduces some complexities and can increase instruction latency.
Instruction vs. Arithmetic Pipelining
While instruction pipelining focuses on processing entire instructions, arithmetic pipelining deals specifically with optimizing arithmetic operations within the ALU or FPU. Both techniques contribute to overall CPU performance but in different ways.
The Future of Instruction Pipelining
As we push the boundaries of computing power, instruction pipelining continues to evolve. Future advancements may include:
- More sophisticated branch prediction algorithms
- Enhanced parallel processing capabilities
- Integration with emerging AI technologies for smarter resource allocation
Conclusion: The Engine of Modern Computing
Instruction pipelining has revolutionized CPU design, enabling the high-performance computing we rely on today. By breaking down instruction processing into stages and executing them in parallel, this technique has paved the way for faster, more efficient computers. As we look to the future, instruction pipelining will undoubtedly continue to play a crucial role in advancing computer architecture and pushing the limits of what our machines can achieve.