{kind=link}

In This Article
What is Microcode?
Microcode refers to the set of microinstructions for the hardware which is not accessible by any program and is usually written on the ROM or Read Only Memory. These instructions control the microprocessor directly.
KEY TAKEAWAYS
- The basic function of a microcode is to perform short register operations at a controlled level. This may include several micro instructions and every such micro instruction may perform one or a couple of micro operations.
- A microcode changes state machine data and instructions into circuit-level operation sequences.
- A microcode is written at the design phase and is stored in several places, which is why it is also called a writeable control store.
Understanding Microcode
Microcode, often expressed as μcode, is actually derived from the machine language interpretation at the lower level.
It plays a significant role in managing the resources of the hardware at the circuitry or register level.
Typically, machine language deduces the machine instructions and sends them to the lowest hardware layer.
It is here that these larger machine instructions are translated and broken into small micro programs. Each of these programs is called microcode.
It is not easy to modify a microcode by using generic programs or by any average programmer.
This is because such tasks need connecting a diverse range of registers.
For that, arithmetic logic units must be used in order to perform the mathematical calculations and the results thus arrived are required to be stored in the register.
In simple terms, a microcode in a processor design refers to the method which introduces a level of computer organization.
This is typically inserted between the Instruction Set Architecture or ISA that is programmer-visible and the Central Processing Unit or the CPU of the computer.
This hardware-level instruction uses machine code instructions of higher level or internal machine sequencing in the finite state in several different digital processing rudiments.
Typically, a microcode is used in general-purpose CPUs but in the recent desktop CPUs it acts simply as a contingency path to process those instructions that cannot be handled by the hardwired and faster control unit.
Residing in the particular high-speed memory, it translates state machine instructions and data or any other input for that matter into detailed sequences of circuit-level operations.
A microcode can be extensive and in that case it may even allow simple and smaller micro architectures to imitate more dominant architectures with higher number of execution units and wider word length.
This eventually offers a much simpler way to realize software compatibility between several products in the processor family.
Typically, there are raw machine code instructions at the lowest layer in the software stack of a computer for the processor.
If the processor is microcoded, then it is the microcode that fetches, decodes, and executes those instructions.
Characteristics
As said earlier, there is a lot of difference between a microcode and a machine code.
Usually, some sort of backward compatibility is retained in the machine code among the different processors in a specific family.
However, a microcode will not run on any other electronic circuitry other than the exact one that it is designated for.
This is because the microcode consists of an intrinsic part of the design of the specific processor itself.
It is for this reason that an assembly language programmer or a high level programmer typically cannot see or make any changes in the microcode.
A microcode is usually written by the engineers at the design phase of the CPU and can be stored in different places such as:
- The Programmable Logic Array structure
- Read Only Memory
- Static Random Access Memory or
- The flash memory.
That is why a microcode is often referred to as a writeable control store. It can be either a read-only or a read-write memory.
If it is a read-write memory then there is a chance of changing the code to rectify the bugs present in the instruction set when the CPU loads it into the control store during the initialization process from a different storage medium.
It can also be done when there is a need to implement a new machine instruction.
The micro-programs that contain a sequence of microinstructions are usually larger than 50 bits.
This allows controlling all the features of the processors at the same time in one single cycle.
It is also designed specially in order to ensure that machine instructions are executed as fast as possible so that it does not degrade the performance of the application programs associated with these instructions.
History
The concept of a control store was first introduced in 1947 through the MIT Whirlwind design.
It was assumed that it would simplify designing computers by moving over and above the ad hoc methods.
This was actually a diode matrix with a 2D lattice. One of them received the control time pulses sent by the internal clock of the CPU while the other connected to the control signals from the gates and other circuits.
However, this concept was further improved by Maurice Wilkes in 1951 where conditional execution was included to it.
This comprised two matrices. One of them produced signals like the control store and the other chose the micro-program instruction set or the particular row of signals to call upon in the subsequent cycle.
According to the conditional execution concept, alternatives can be chosen in the second matrix by only one particular line in the control store.
Therefore, these control signals were restrictive on the perceived internal signal.
This feature is called microprogramming or micro coding.
Reasons to Develop a Microcode
One of the most significant aspects of the microcode is that it helps the computer designer to build machine instructions but for that they do not need to develop electronic circuits.
This is a good enough reason to develop a microcode in the first place.
A microcode also helps in separating the machine instructions from the primary electronics.
This further helps in designing or altering the instructions more easily and freely.
Apart from that, the microcode will also help in diminishing the complications in the computer circuits by building a complex set of multi-step instructions.
Another significant reason to develop a microcode is to make the process of designing and debugging a processor simpler.
It helps in creating the control logic for the CPU.
Originally, the instruction sets of the processor were hardwired which meant that the machine instructions needed to be fetched, decoded, and executed at every step including reads, writes, and even while calculating the operand address.
And, the entire process was managed directly by a rather negligible state machine circuitry and the combinational logic.
There is no doubt that this process is effective but it also needs very powerful sets of instructions to be used with complex operations and multi-step addressing.
This made it quite difficult for the designers to debug and design a processor.
The difficulty level was further enhanced when heavily encoded irregular instructions with varied lengths were used.
A microcode can ease the process by defining the programming model and behavior of the processor through the routines of the micro-program.
This eliminated the need for a dedicated circuitry.
The microcode in these cases could be changed easily even in the later stages of the design process as opposed to the hardwired CPU design that were very difficult to change. Overall, this simplified the process of designing a CPU.
The microcode incorporates the programmer-visible structure in synchronization with the hardware.
The hardware for that matter does not need to have any definite relationship with the visible architecture.
Once again, this makes it much easier to incorporate any available Instruction Set Architecture on an extensive selection of hardware micro-architectures underlying.
Most importantly, the microcode lowers the cost of rectifying defects and bugs in the process by making changes in it.
Typically, replacing a part of the microcode will fix a bug without needing to make any changes in the hardware wiring or logic.
Implementation
When a microcode is implemented, every microinstruction in it provides the bits that are necessary to manage the internal functional elements that make a CPU.
The benefit of it is that the CPU now has more specialized internal control while running a program.
A microcode is implemented by dividing it into several parts in order to simplify the complicated electronic design or programming challenge. These are:
- An I-unit that decodes instructions in the hardware in order to figure out the microcode address so that the instruction can be processed in parallel with the E-unit
- A micro sequencer that selects the subsequent word of the control store
- A register set that holds the data of the CPU
- An arithmetic and logic unit to perform the calculations and
- A memory data register and a memory address register to access the main storage of the computer.
All these elements together constitute the execution unit and almost all modern CPUs come with a lot of such execution units.
However, even the simplest of computers come with at least a single read and write memory unit and another unit to carry out the user code.
Often, these units are built on a single chip of fixed width.
These units then form a slice in the execution unit and are therefore called bit slice chips.
There are a whole lot of wires that are called a bus that connects the parts of the execution units to the entire unit.
Basic software tools are used to develop and implement the microcode such as a micro assembler.
This allows the designer to symbolically characterize the table of bits.
A compiler cannot be used for that matter due to the close association of a microcode to the underlying architecture.
There is also a simulator program used to carry out the bits in a similar manner as the electronics.
This allows a lot of freedom to the designers to debug a microcode.
When everything is done, the micro-program is tested extensively and is used as an input to a computer program so that some logic is constructed to generate the same data.
This computer program is very much the same as the ones that are typically used to optimize a PLA.
However, it is not always necessary to have a fully optimized logic.
Even a heuristically optimized and speculative logic can drastically lower the number of transistors needed for a ROM control store.
In turn, this lowers the cost to produce a CPU as well as reduces the amount of electricity consumed.
Updates and its Effects
The manufacturers of the processors periodically release updates to the CPU microcode for security and stability reasons.
These updates offer bug fixes that can restore and maintain the crucial stability of the system.
Without these bugs fixed you may encounter undesired and unexpected system hangs or even crashes and the causes of these may be very difficult to trace.
Therefore, you should always install these updates if you are serious about system stability.
Typically, these updates are shipped with the firmware of the motherboard and are applied while initialization of the firmware.
However, it can also be loaded through the operating system.
Usually updates of microcode do not continue across reboots.
Therefore, in a dual-boot system, if it is not provided through the BIOS, the operating systems need to deliver it.
Sometimes, the Original Equipment Manufacturers may not release updates in a periodic manner for the firmware.
Also, the old system may not get such updates at all. It is for this reason, specific operating systems, such as Linux, add such updates in their kernel.
The microcode loader of Linux however supports three specific loading methods such as:
- Early loading updates during boot and before the initramfs stage, which is the preferred method
- Late loading updates after booting which can be quite dangerous because the processor may have tried using the bugged instruction set already and
- Built-in microcode in the kernel.
However, late loading updates can be used for new microcode which does not need booting the system.
Writing a Microcode
Writing a microcode is also called micro programming and the code written for is called the micro program for the particular computer.
While writing a microcode a micro assembler is used and it is needed to keep in mind that each of the instructions written should be labeled and not numbered.
There are also a few other important aspects to remember such as:
- Every microinstruction should list all the control lines that are needed to be enabled and not left at zero
- Every microinstruction should be able to perform If… Then… Else… function and also jump to a particular microinstruction subsequent to it if the control value or some data in it mentions specifically about it
- The microcode should be able to switch depending on the specific opcode in the instruction and
- At the opening of every processor instruction the value of the subsequent instruction must be loaded in the IR.
Where is a Microcode Stored?
A microcode can reside in different high-speed memory.
As said earlier, a microcode is usually stored in the Read Only Memory or ROM of the computer, and it can be an Erasable Programmable ROM or EPROM, Programmable ROM or PROM or any other.
It can also be stored in the Programmable Logic Array structure. Sometimes it can be stored in both the PLA and the ROM.
Apart from that, a microcode can be also stored in the Static RAM or flash memory.
How to Find a Microcode Version?
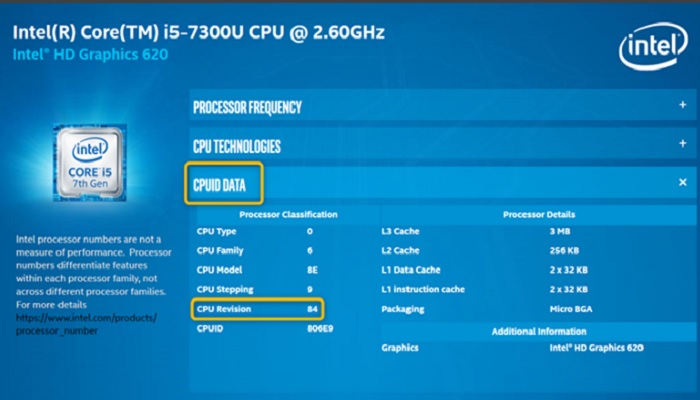
Typically, you can use the Intel Processor Identification Utility program to find the version of the microcode.
This utility tool will report the CPUID information of the processor that is installed in your computer.
This tab is to be found under the CPUID DATA tab of the utility tool.
The CPUID DATA section will list the version of the microcode. It can be referred to as CPU Revision and may be written as 0x84, if the version of the microcode is 84, for example.
Are Microcode Updates Permanent?
No, microcode updates are not permanent and usually are deleted when you reset the CPU.
This is because the microcode updates, as said earlier, are usually delivered through the firmware updates of the motherboard.
When the computer system boots up, the firmware of the motherboard automatically updates the microcode.
Therefore, if you want to roll back the updates to the microcode you will need to roll back the firmware of the motherboard.
What is a Horizontal Microcode?
A horizontal microcode is that in which every microinstruction controls the processor elements and needs very little or no decoding for it.
In such a microcode, each micro-operation in every microinstruction is represented by a single bit.
This type of microcode is usually incorporated in a quite wide control save.
Therefore, it is not extraordinary for every exertion to be 56 bits or more.
This means that the horizontal microcode contains more bits and is wider.
However, it also takes up more storage space than a vertical microcode.
Usually, in a horizontal microcode, the program word consists of groups of bits that are quite tightly defined.
What is a Vertical Microcode?
A vertical microcode is that which needs combinatorial logic for extensive decoding.
Every microinstruction in a vertical microcode is encoded.
This means that the bit field may pass through the combinatory logic in-between.
This actually creates the control signals for the internal components of the CPU such as the registers, ALU or Arithmetic Logic Unit and others.
In a vertical microcode all of the micro operations are assembled into fields.
This clustering ensures that there is one, and only one, active micro-operation in one field irrespective of the state.
It is then a unique field value is given to every micro-operation in the field.
The field bits of the micro-operation are typically the output of the microcode memory that reaches the decoder and the output of this decoder is the micro-operations that are generated directly under the horizontal microcode.
Conclusion
With all that said and explained, it brings to the end of this article but surely, by now you should be more knowledgeable about the microcode than you were before reading this article.