{kind=link}

In This Article
What is Instruction Pipeline?
In a computer, instruction pipeline typically refers to the technique by which Instruction Level Parallelism or ILP is implemented in a single processor.
Technically, in this process each part of the CPU is kept busy with some sort of instruction by splitting all of the incoming instructions into a set of sequential steps.
This basically creates the instruction pipeline. Each of the different parts of the instructions is processed by different processor units in parallel.
KEY TAKEAWAYS
- Instruction pipelining refers to a process used in modern microprocessors and microcontrollers to enhance the throughput.
- This technique systematizes the instructions to be performed so that the execution of the succeeding instruction overlaps the execution of the current instruction.
- The instructions are divided into different phases such as instruction fetch and decode, operand fetch and execution, and operand store. All these phases are performed in parallel in an instruction pipeline.
- The process prevents two or more instructions performing the same stage in the same clock cycle even though it allows several instructions to perform at the same time.
- Instruction pipeline may stall due to some reasons which may result in different issues with data, resources and control.
Understanding Instruction Pipeline
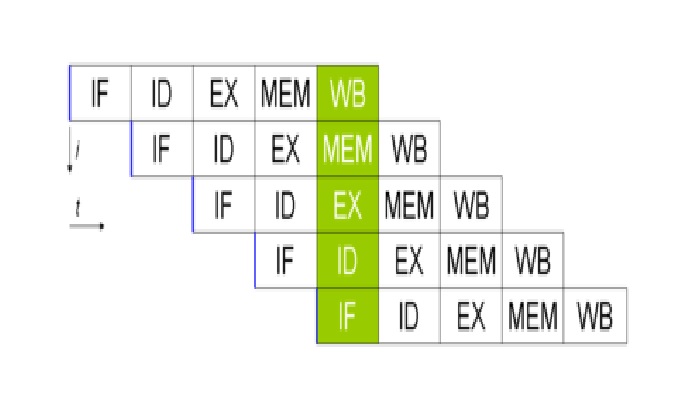
An instruction pipeline refers to a specific arrangement where an instruction is divided into several smaller parts and the consecutive instructions are read from the memory.
While this happens, earlier instructions are implemented in the other segments of the pipeline.
Pipelining can occur not only in the instruction stream but also in the data stream.
This may result in an overlap in the fetch and execute operations. In such situations, typically, operations are performed simultaneously.
Instruction pipeline is needed in most of the computers that need to handle a lot of complex instructions, process them and produce the results fast.
Ideally, the instruction pipeline helps the processors to process every instruction through a series of steps that include:
- Fetching the instruction from the memory location
- Decoding the instruction
- Calculating the useful address
- Fetching the necessary operands from the memory locations
- Executing the instruction
- Storing the result in a proper location.
Each of these steps mentioned above is carried out in a specific segment during the processing of the instruction.
And, there may be times when different steps may take different times for it.
What is more, there may also be a few times when two or more of these functions need to access the memory at the same time.
In such a situation, one particular segment will have to wait until the other is done with the memory.
There can be two types of segment units in the construction of a computer, namely:
- An instruction fetch unit and
- An instruction execution unit.
The instruction fetch unit is implemented with a FIFO buffer and therefore it can form a queue instead of an instruction stack.
The advantage of this method is that the control unit augments the Program Counter when no memory is created by the implementation unit.
This helps in reading the successive instruction from the memory location with its address value.
The instructions are put in the FIFO buffer so that they are implemented on a FIFO basis.
This helps in locating an instruction flow in a queue to hang around for interpreting and phasing by the implementation section.
This queue structure of the instruction stream is a much more effective approach since it helps in reducing the average access time taken by the memory to read the instructions.
The control unit can start the following fetch operation as and when there is a region in the FIFO buffer.
It can then be regulated and derived from the buffer for the implementation unit to work on it.
However, in an instruction pipeline, there is one particular possibility, which is an additional event that may produce a branch out of the sequence.
In order to make sure that such an incident does not happen, the pipeline needs to be clear and all of the instructions that are read after the branch instruction from the memory should be rejected.
Instruction Pipeline Example
One of the most common examples of such type of instruction pipeline is a 4-segment instruction organization. This means that the instruction cycle is completed in four segments where two or more of them may make it as a single one.
Ideally, an instruction pipeline will be more effective if only the distribution of instruction cycles is of equal duration.
In this type of an arrangement, the instruction will be decoded in combination with the computation of the effectual address into a single segment. In each segment, the functions will be performed as follows:
- Segment 1 – This part is the instruction fetching segment where the First In, First Out or FIFO buffer is used.
- Segment 2 – In this segment, the instruction that is fetched from the memory location is decoded and the effective address is eventually calculated with the help of a different arithmetic circuit.
- Segment 3 – In this segment, the operand is fetched from the memory.
- Segment 4 – In this last segment of the instruction pipeline, the instruction is executed, finally.
How Do Instruction Pipelines Work?
An instruction pipeline works by executing several instructions simultaneously. It actually reads the instruction from the memory, while the earlier instructions are worked upon in other parts of the pipeline.
In most general cases, it works in different stages as follows:
- The instruction is fetched from the memory in the first clock cycle
- The instruction is decoded in the second clock cycle
- The effective address is calculated
- The operands are fetched from the memory
- The instructions are executed
- The final result is stored.
Due to the pipelining, the fetching and decoding phases overlap.
If there is a third instruction, it will typically be a branched instruction, and when this will be decoded, the fourth instruction will be fetched at the same time.
However, being a branched instruction, it may point to another instruction when it is being decoded.
This means that the pipeline will put the fourth instruction on hold till the time the branched instruction is executed.
It will be written back when it gets executed. All other phases carry on as normal.
What are the Situations in which an Instruction Pipeline can Stall?
Stalling of an instruction pipeline is also called a pipeline bubble and it usually happens during specific situations when the execution of the instructions in the pipeline is either delayed or has stopped.
Depending on the conditions, when an instruction pipeline stalls, it can cause different hazards.
There are several reasons for an instruction pipeline to stall. For example:
- The instruction pipeline can stall when two or more instructions in it want to access the same resource. This will cause a resource hazard, also known as a structural hazard.
- The pipeline may also stall when there is a conflict created while accessing the location of the operand. This causes data hazard, which is also called data dependency.
- And finally, an instruction pipeline can also stall when it is unable to predict branches in an instruction. This causes a control hazard, which is also called a branch delay or a branch hazard.
Why is Instruction Pipelining Needed?
One of the most significant reasons to use an instruction pipeline is that it keeps every part of the CPU busy.
This further ensures that the amount of work done in a given moment by the processor is more which reduces its cycle time and eventually increases the instruction throughput.
Another significant reason to use the instruction pipeline is to increase the efficiency of the overall system.
Ideally, in a computer, every instruction is processed in different stages, and each of these different stages is performed separately and is managed by different parts of the hardware.
This means that the fetching unit will have no more work to do and sit idle after it has fetched one instruction from the memory and passed it over to other segments of the hardware for carrying out the other stages of the process.
It will not be able to fetch the following instruction until the previous process is completed and the operand is stored in the right place.
This will reduce the efficiency of the system. However, instruction pipelining will not allow this to happen because its implementation will allow different hardware parts to process different parts of the instruction at the same time.
Apart from increasing the instruction throughput, an instruction pipeline is also needed for other fundamental reasons which include completing the execution of an instruction in each clock cycle.
Types of Pipeline Conflicts in the Instruction Pipeline
The different types of pipeline conflicts that can occur in an instruction pipeline include timing variations, branching, data dependency, and interrupts.
There are several different reasons for such conflicts to occur but there are also specific ways to overcome them. However, the different types of instruction pipeline conflicts are explained hereunder.
Timing variations:
Timing variations occur because, ideally, all stages of instruction processing do not take the same amount of time, especially when different operands need to be handled. This results in conflicts in the pipeline.
Data conflicts:
Data conflicts occur especially when there are many instructions in partial execution within the instruction pipeline, and more so when all of them need to access the same data.
It is very important to make sure that the subsequent instruction does not access the data before the current operation is completed. Otherwise, this will result in an incorrect result.
Data dependency:
Data dependency conflicts occur in the instruction pipeline when a particular instruction relies on the result of an earlier instruction but the result is not readily available for it to go ahead with the processing.
Branching:
Ideally, it is needed to know the instruction in order to fetch and execute the following instruction. But, in the case of a conditional branch where the result of it will lead to the following instruction, the subsequent instruction may not be known till the current instruction is executed, resulting in a conflict in the instruction pipeline.
Interrupts:
Interrupts can also create conflicts in an instruction pipeline and affect the execution of the instruction by setting unwanted instructions in the stream of instructions in the pipeline.
Advantages
- Reduced cycle time of the processor
- Increased throughput of the system
- Enhanced system reliability
- Simultaneous execution of multiple instructions.
Disadvantages
- Complex design
- Expensive
- Higher instruction latency.
Instruction Pipeline Vs Arithmetic Pipeline
- An instruction pipeline is usually asynchronous in nature, but, in comparison, an arithmetic pipeline is generally synchronous
- An instruction pipeline is usually linear, while in comparison, an arithmetic pipeline is nonlinear
- An instruction pipeline refers to the overlapping of instructions in the data path of the processor, but, in comparison, arithmetic pipelining refers to the overlapping of computation within the Arithmetic Logic Unit or the Floating Point Unit
- The set of instructions is executed by overlapping the fetch, decode, and execute phases in the instruction pipeline but, in the arithmetic pipeline diverse segments process them separately using multiplication, floating point operations, and others
- Execution of instructions in the instruction pipeline depends on the distinct instruction cycle for the CPU, but, in comparison, the arithmetic pipeline does not and divides a problem into subparts to be processed in the pipeline.
How Many Processors are Used in the Instruction Pipeline?
There is only one processor used in the instruction pipelining. This technique actually keeps every part of the processor busy by dividing the incoming instructions into different parts or a set of sequential steps.
Conclusion
The instruction pipeline allows dividing an instruction into different segments and processing them in different stages by overlapping fetch, decode, and execution operations.
This technique is used to increase the performance of the processor with a much higher instruction throughput.